Valeurs extrêmes en SHS
Journée MAD - 26/05/2025
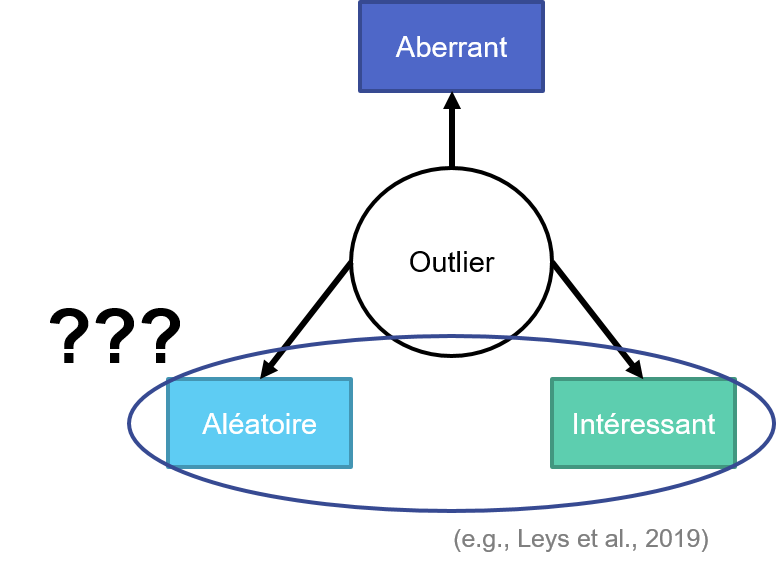
Outliers - définition
Valeurs extrêmes ou Valeurs aberrantes ? 
Outliers - pourquoi cette question ?
Tout démarre de notre pratique

Outliers - pas simple de répondre à cette question
Aguinis et al. 2013 proposent 14 définitions différentes

Extraits :
Valeur extrême par construction : Valeurs inhabituellement grandes ou petites par rapport aux autres valeurs du même construit. En général, en queue(s) de distribution.
Valeur extrême d’intérêt : Des points de données précis qui se trouvent à distance des autres points de données et qui peuvent contenir des informations valables ou des connaissances inattendues.
Valeur extrême liées à des analyses (modèles, cluster, etc.) : par exemple, valeurs extrêmes résultant de la conduite d’une analyse en cluster.
Outliers - pas simple de répondre à cette question
Outliers - quels impacts ?
Catastrophique (Cowell & Victoria-Feser, 1996a)

Outliers - quels impacts ?
Négligeable (Cowell & Victoria-Feser, 1996b) 
Outliers - quels impacts ?
Ca dépend (André, 2022; Hlasny & Verme, 2018; Karch, 2023) 
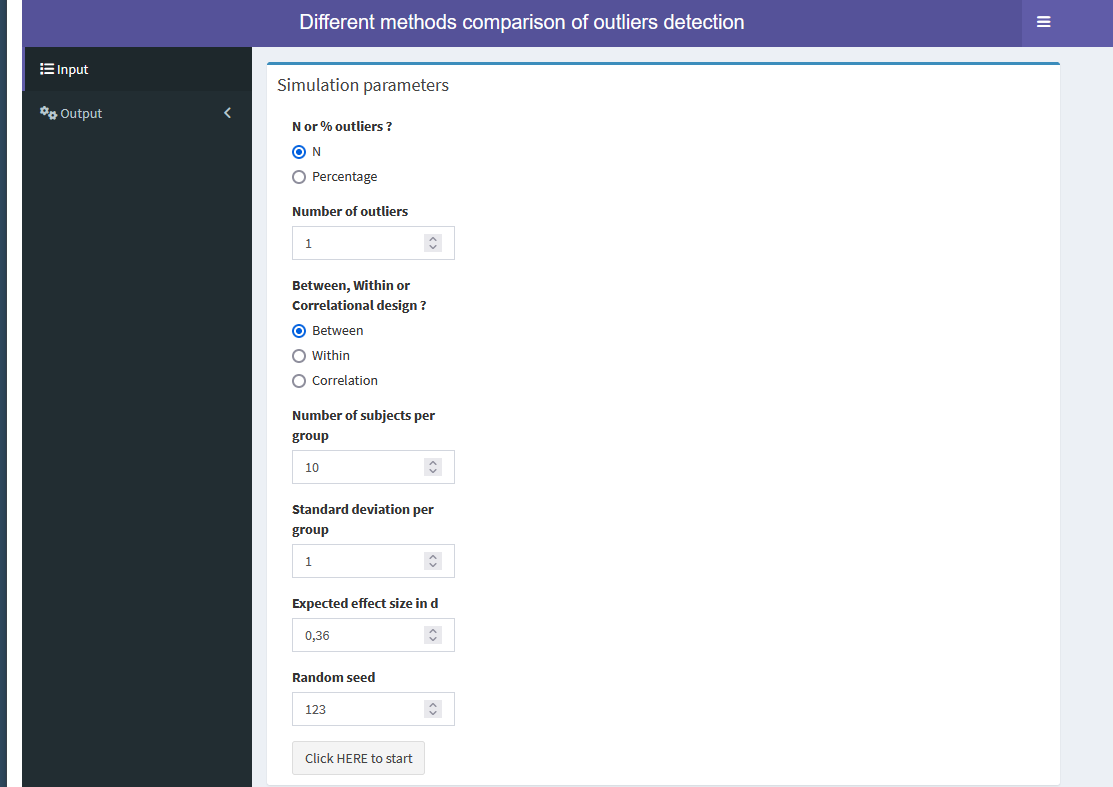
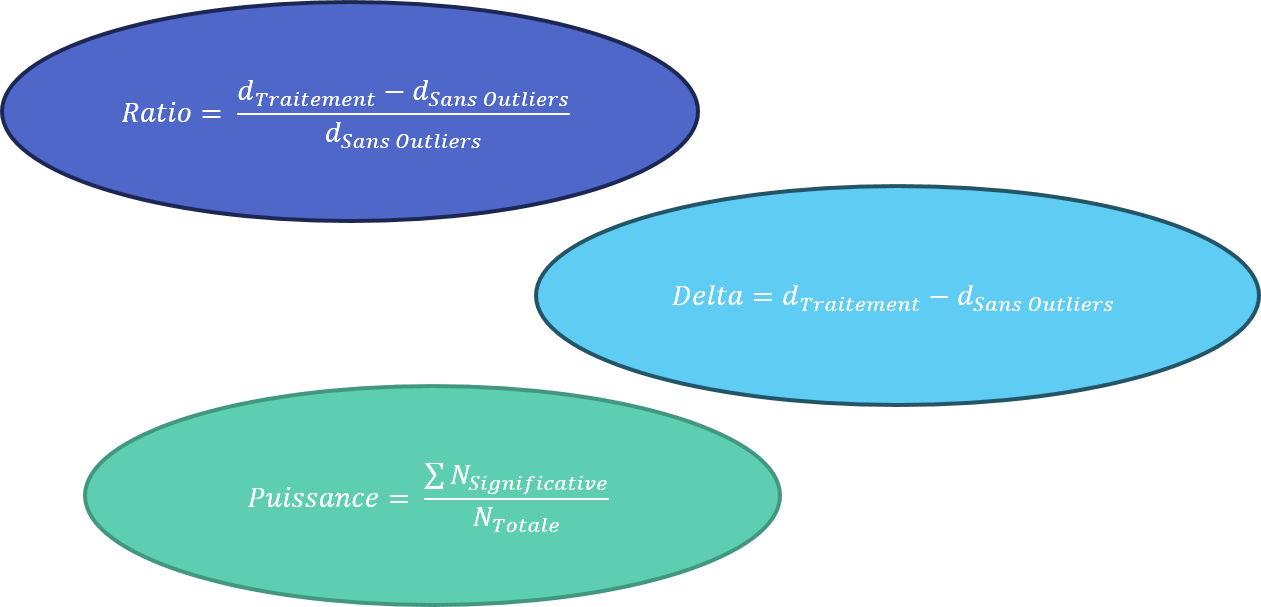
Première partie : Outliers dans le cas de designs simples
Comparaison des méthodes sur 3 designs :
- Inter-groupes
- Intra-groupes
- Corrélations
Première partie : Outliers dans le cas de designs simples

Première partie : Outliers dans le cas de designs simples
Deuxième partie : Outliers dans le cas de designs multivariés
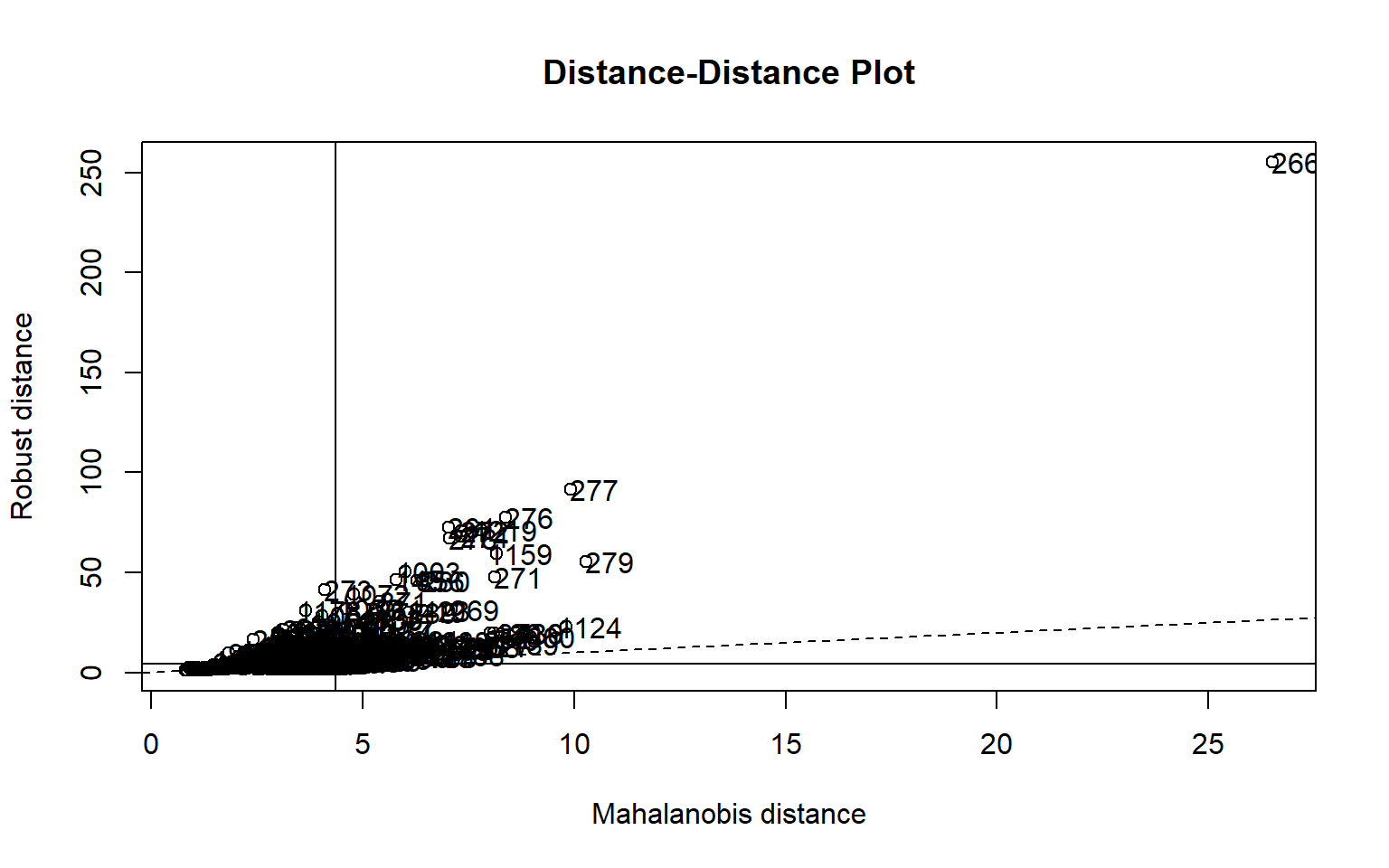
Deuxième partie : Outliers dans le cas de designs multivariés
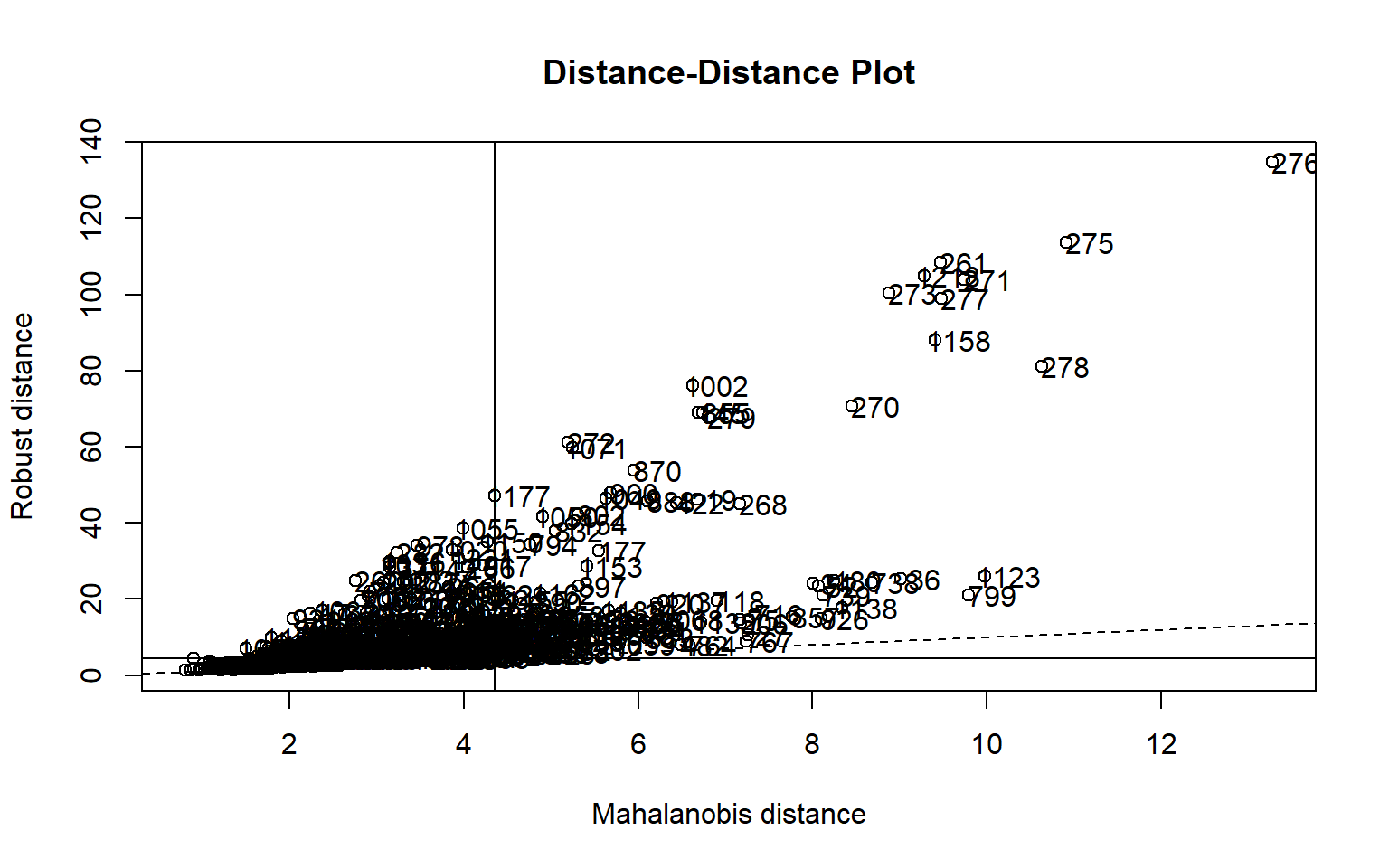
Troisième partie - méthodes de détection alternatives
Package DHARMa : (Hartig, F., 2024)

Approche par simulation
Merci de votre attention

Echanges et discussions
